
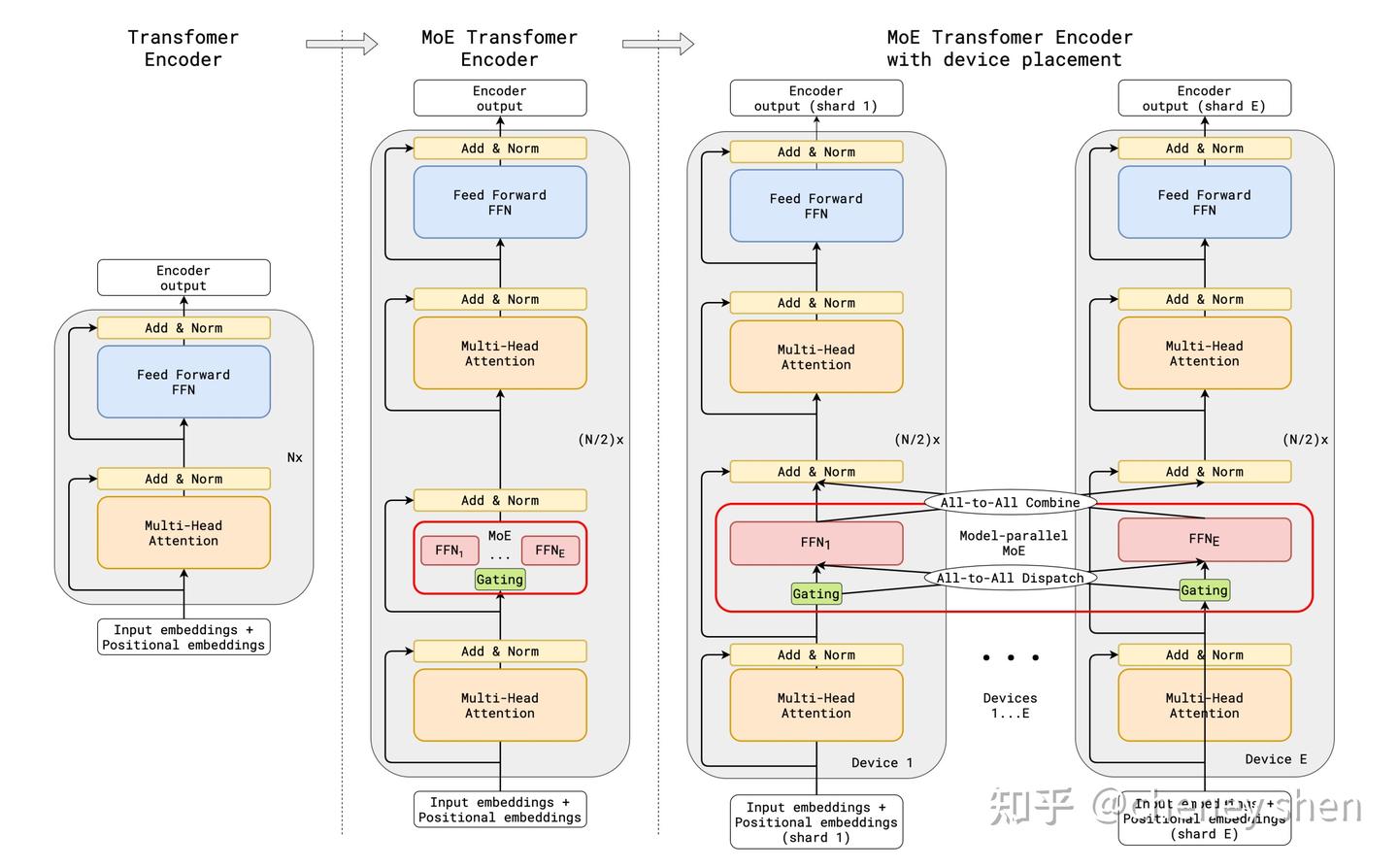
在大模型领域里越来越火的技术——MoE(Mixture of Experts)。deepseekV3一鸣惊人,除了效果上吊打同级别模型,另外一个原因就是deepseek使用了MOE的架构,模型参数量很大(671B),但是实际激活的参数却只有37B。为啥MOE这么牛B呢?下面咱们会详细深入的聊一聊。
这篇文章会有点长,信息量可能比你上次熬夜 debug 留下的黑眼圈还要大,但请放心,我会尽量用“人话”,掺杂一些(可能并不好笑的)梗和比喻,带你彻底搞懂 MoE 这个磨人的小妖精。ready?go!
(全文18000-字,预计阅读时间:取决于你摸鱼的频率,但内容绝对管饱!)
第一章:为啥需要 MoE?——“大”模型的“大”烦恼
咱们先来谈谈背景。近年来,大模型(LLM)就像打了激素一样疯狂生长,参数量从几亿、几十亿飙升到几千亿甚至万亿级别。模型越大,能力越强,这似乎成了一条“简单粗暴”的定律(Scaling Law)。
但是,这种“大力出奇迹”的模式带来了一个巨大的问题:贵!太TM贵了!
训练成本高: 训练一个万亿参数的模型,需要的计算资源(GPU/TPU 集群)和时间简直是天文数字,烧钱速度堪比碎钞机。只有少数巨头公司玩得起。
推理成本高: 即便模型训练好了,每次用户问个问题(进行一次推理),模型都需要调动它那庞大的参数进行计算。想象一下,你只是想问个“今天天气怎么样”,结果模型内部几千亿个“神经元”全体起立,开了一场盛大的内部会议,然后才告诉你“晴”。这效率,这能耗,谁顶得住啊?
核心矛盾: 我们想要模型能力强(需要大参数量),又想让它运行得快、成本低(计算量不能太大)。这听起来是不是有点“既想马儿不吃草,又想马儿跑得快”一样矛盾,核动力牛马也扛不住啊。
传统(Dense)模型的困境: 在传统的 Transformer 模型(比如早期的 GPT-3)中,每一层的计算,尤其是前馈神经网络(Feed-Forward Network, FFN)部分,都需要所有的参数参与运算。这种模型我们称之为稠密模型(Dense Model)。
举一个不太恰当的 :你现在是一个创业公司的 CEO(这个 FFN 层),公司对内对外所有大事、小事、琐事(输入一个 token)都需要你亲自处理,从头到尾,得动用你全部的知识储备(所有参数)。初创公司还好,随着你公司规模越来越大,业务越来越多(输入序列长),要你处理的事情也就指数上升了,就算你真是核动力的,恐怕也得累冒烟。公司想扩大业务(增加参数),就得给你吃更多补品,打更多激素,再喂点放射性元素(更多计算资源),那这成本就直线上升了。

传统稠密模型:每一个输入都要经过所有参数,计算量巨大!
面对这种“又大又慢又贵”的窘境,研究者们开始思考:能不能让模型“聪明”一点?每次处理输入时,能不能只动用部分相关的“脑细胞”(参数),而不是每次都“全体总动员”?
MoE: “正是在下!”
MoE 提供了一种条件计算(Conditional Computation)的思路。它的核心思想是:我有很多参数,但我一次只用一小部分。就像你的公司越干越大,里面有很多不同的部分,每个部门都有不同领域的专家(财务、法务、技术、算法……)。当一个客户带着特定问题来时,前台(Gating Network)会判断这个问题属于哪个领域,然后只把问题交给那几个相关部门的专家(Activated Experts)去处理,其他部门的人则可以继续“摸鱼”(不参与计算)。
这样一来,公司(模型)的总知识储备(总参数量)可以非常庞大,因为它拥有各个领域的专家,但处理具体问题时的开销(计算量)却相对较小,因为只有少数专家在工作。
听起来是不是很妙?接下来,我们就深入 MoE 的内部,看看它是怎么实现这种“智能分派”和“专家坐诊”的。
第二章:MoE 的核心组件:专家(Experts)与门控网络(Gating Network)
MoE 模型的核心思想是“分而治之”,它主要由两个关键部分组成:
专家网络(Experts): 一群“身怀绝技”的小网络。
门控网络(Gating Network): 一个“调度员”,负责决定该把任务交给哪些专家。
2.1 专家网络(Experts):术业有专攻(理论上)
是什么: 在 Transformer 模型中,MoE 通常被应用在 FFN 层。原本一整个巨大的 FFN 层,被替换成了一组(比如 8 个、16 个、64 个甚至更多)规模较小的 FFN 网络。这些小 FFN 就被称为“专家”(Experts)。
结构: 每个专家本身通常就是一个标准的 FFN 结构(比如两层线性层加一个激活函数),和原来那个大 FFN 没什么本质区别,只是“瘦身”了很多。所有专家通常具有相同的结构,但它们的参数(权重)是独立的,在训练过程中会各自学习。
作用: 每个专家理论上被期望学习处理输入数据的某一方面或某种模式。比如,在语言模型里,一个专家可能擅长处理语法结构,另一个可能擅长处理专有名词,还有一个可能对情感色彩比较敏感等等。(当然,这种理想化的“功能划分”在实际中是否真的那么清晰,是存在争议的)。
关键点: 专家数量可以很多,从而使得模型的总参数量可以远超同等计算量的稠密模型。例如,一个 MoE 模型可能有 8 个专家,每个专家的参数量和稠密模型的 FFN 差不多,那么 MoE 层的总参数量就是稠密模型的 8 倍!但是,在处理每个输入 token 时,我们并不会让所有 8 个专家都工作。
2.2 门控网络(Gating Network):智能调度,you can you up!
这是 MoE 的“灵魂”所在,它决定了对于每个输入,哪些专家应该被激活。
是什么: Gating Network 通常是一个非常简单的网络,甚至可以只是一个线性层。它的输入是 MoE 层接收到的 token 的表示(representation),输出则是一组“权重”或者说“概率”,对应到每个专家。
作用: 根据当前的输入 token,Gating Network 会判断哪些专家最“适合”处理这个 token。它会给每个专家打一个“分数”(或者说权重),分数越高的专家,意味着 Gating Network 认为它越应该参与这次计算。
机制(以 Top-K Gating 为例):
输入: MoE 层接收到一个 token 的向量表示 。
计算门控值(Logits): Gating Network(通常是一个线性层,权重为 )处理这个输入,得到一个向量 。这个向量 的维度等于专家的数量 。 中的每个元素对应第 个专家的“原始分数”。
计算概率/权重(Softmax): 为了让这些分数变成类似概率的形式(总和为 1,且非负),通常会使用 Softmax 函数: 。其中 是一个 维的向量 表示第 个专家的被选中概率(或者说重要性权重)。
选择 Top-K 专家: 在现代的 MoE 实现中(尤其是为了稀疏性),并不会让所有专家都参与计算(即使它们的权重 > 0)。而是采用一种叫做 Top-K Gating 的策略。也就是说,Gating Network 只选择得分最高的 K 个专家(通常 K 很小,比如 1 或 2)。
为什么是 Top-K? 这就是实现稀疏激活(Sparse Activation)的关键!如果我们让所有 的专家都参与计算,那计算量还是很大。Top-K 保证了无论专家总数 有多大,每个 token 始终只由个专家处理。这就大大降低了计算量!
具体操作: 找到向量中值最大的个元素的索引(Indices),记为 。
重新加权(可选但常见): 选出的 Top-K 个专家的原始 Softmax 权重 通常会被重新归一化(renormalize),使得它们的和为 1。这一步是为了确保最终输出的权重和为 1。设 为仅包含 Top-K 专家原始权重的向量,则最终使用的门控权重 为: 。这样,我们得到了一个稀疏的权重向量 ,其中只有 个非零值,且它们的和为 1。
再举个不太恰当的 :Gating Network 就像一个经验丰富的前台接待。客户(token )来了,前台( )快速打量一番(计算 ),然后根据客户的需求( 的特征)在心里给所有部门的专家(财务、法务、技术、算法...)打分(Softmax 得到 )。但公司规定,为了效率,每次只能叫两位专家来开会(Top-K=2)。于是前台就挑出得分最高的两位(找到 ),并告诉这两位专家他们各自的重要性(计算 )。其他部门的专家?继续带薪摸鱼!
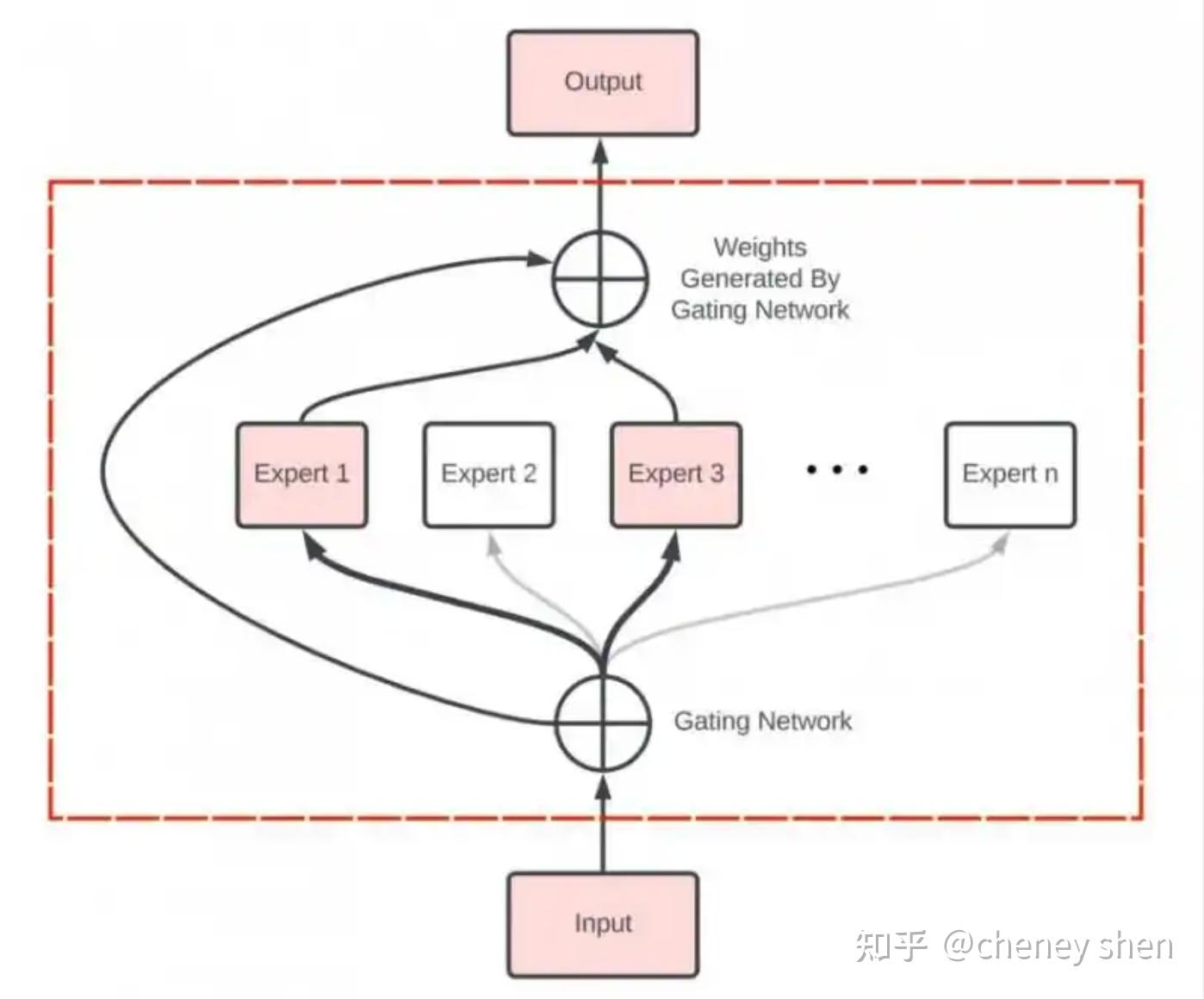
Gating Network:智能分配任务,只激活少数(Top-K)专家
说了半天,来段伪代码吧,咱们程序员看代码比看文字舒服,您说是不
import torch
import torch.nn.functional as F
class TopKGating(torch.nn.Module):
def __init__(self, input_dim, num_experts, k=2):
super().__init__()
self.k = k
# 线性层 W_g,输出维度是专家数量
self.gate_linear = torch.nn.Linear(input_dim, num_experts)
def forward(self, x):
# x shape: (batch_size, sequence_length, input_dim)
# 或者处理单个 token 时: (batch_size, input_dim)
# 为了简化,我们假设处理的是一批 tokens (batch_size * sequence_length, input_dim)
# 1. 计算门控值 (logits)
# shape: (num_tokens, num_experts)
logits = self.gate_linear(x)
# 2. 计算 Softmax 概率 (用于选择 Top-K)
# shape: (num_tokens, num_experts)
probs = F.softmax(logits, dim=-1)
# 3. 选择 Top-K
# top_k_probs: 最高的 K 个概率值
# top_k_indices: 最高的 K 个概率对应的专家索引
# shape of both: (num_tokens, k)
top_k_probs, top_k_indices = torch.topk(probs, self.k, dim=-1)
# 4. 创建稀疏的门控权重 G
# 初始化一个全零张量
# shape: (num_tokens, num_experts)
gating_weights = torch.zeros_like(probs)
# 使用 scatter_ 将 top_k_probs 填充到对应 top_k_indices 的位置
# 这个操作有点 tricky,它会把 top_k_probs 的值放到 gating_weights 的相应位置
gating_weights.scatter_(1, top_k_indices, top_k_probs)
# 5. 重新归一化 Top-K 权重 (使其和为 1)
# 计算每个 token 的 Top-K 概率之和
# shape: (num_tokens, 1)
norm_factor = gating_weights.sum(dim=-1, keepdim=True)
# 加上一个小的 epsilon 防止除以零
norm_factor = norm_factor + 1e-6
# 归一化
# shape: (num_tokens, num_experts), 只有 K 个位置非零且和为 1
final_gating_weights = gating_weights / norm_factor
# 返回: 最终的稀疏门控权重 G 和 被选中的专家索引 I
# top_k_indices 对于实际路由 token 很重要
return final_gating_weights, top_k_indices 这段代码展示了 Top-K Gating 的核心逻辑:计算分数、Softmax、选 Top-K、然后(可选地)重新归一化权重。注意,实际的 MoE 实现会更复杂,涉及到如何高效地将 token 路由到对应的专家 GPU 上等工程问题,但核心思想就是这样。
第三章:MoE 层如何工作:整合专家与门控
现在我们有了专家(一群随时待命的小 FFN)和门控网络(一个智能调度员),它们如何协同工作形成一个完整的 MoE 层呢?
MoE 层的前向传播过程:
假设我们有一个 MoE 层,它有 个专家 ,一个 Gating Network , 并且我们采用 Top-K=k 的策略。对于输入的一个 token 的表示 :
门控决策: 输入 首先被送到 Gating Network。
这里 是一个维的稀疏向量,只有 个非零元素(对应 Top-K 专家的权重,且和为 1)。 是这 个被选中专家的索引。
专家处理: 输入只被发送给 Gating Network 选中的那个专家进行处理。
注意:其他的 个专家完全不参与计算,它们的计算量为零!这就是计算稀疏性的来源。
加权组合: 个被激活专家的输出 ,根据 Gating Network 给出的相应权重进行加权求和,得到 MoE 层的最终输出 。
或者更完整地写成:
(因为对于 , ,所以 )
整个过程的数学表达:
对于输入 ,MoE 层的输出可以表示为:
其中是 Gating Network 的输出向量(经过 Top-K 选择和归一化,是稀疏的), 是第个专家的输出。
还记得咱们举的 么,比喻:
客户(token )来到前台。
前台(Gating Network)判断后,说:“这个问题,我看让技术部门的专家( )和法务部门的专家( )来处理比较好,技术占 70% 权重( ),法务占 30%( )。”(假设 Top-K=2)。其他专家(算法、财务等)继续摸鱼。
客户的问题 被同时发给技术专家和金融专家 。他们各自独立地进行分析,分别给出了自己的解决方案和 。
前台将两份方案汇总,按照之前定好的权重进行融合:最终方案 。这个最终方案就是 MoE 层的输出。
与稠密 FFN 层的对比:
稠密 FFN:。所有参数都参与计算。计算量约为 (其中 是模型隐藏层维度, 是 FFN 中间层维度)。
MoE FFN (Top-K):。只有 Gating Network 和 个专家参与计算。假设每个专家的 FFN 结构与稠密模型类似(但可能更小,或者说被分摊到 N 个专家中),其计算量大致为 Gating Network 的计算量 + 单个专家的计算量 。
关键优势体现: 假设稠密 FFN 的计算量是 。MoE 有 个专家,每个专家的计算量是 。Gating 计算量是 。MoE (Top-K) 的计算量大约是 。 如果设计 MoE 时,让 (即所有专家加起来的“潜力”和原来稠密层差不多),那么 MoE 的计算量大约是 。由于 K 通常很小(如 1 或 2),且通常远小于 ,所以 MoE 的计算量可以远小于一个拥有 N 倍参数的稠密模型的计算量。
换句话说,MoE 允许模型拥有巨大的总参数量(潜力大),但在实际运行时只激活一小部分,从而保持较低的计算成本(运行快、省钱)。 这就是 MoE “鱼与熊掌兼得”的秘诀!
第四章:MoE 为什么有效?—— 深入剖析优势
我们已经了解了 MoE 的基本原理和工作方式。现在,让我们来深入探讨一下,为什么这种看起来有点“花里胡哨”的结构能在大型模型中取得成功?
4.1 计算效率:稀疏激活的力量
这是 MoE 最核心、最直接的优势。
条件计算: 正如前面反复强调的,MoE 不是对每个输入 token 都使用模型的全部参数,而是根据输入动态地选择一小部分(Top-K)专家来处理。
FLOPs 节省: FLOPs(Floating Point Operations per Second)是衡量计算量的常用指标。对于一个有 N 个专家、选择 Top-K=k 的 MoE 层,其前向传播的计算量大致只相当于一个规模为其的稠密层(这是一个非常粗略的类比,主要是指专家部分的计算量)。例如,Mixtral 8x7B 模型,虽然总参数量是 (实际略有不同,因为共享参数),但每次推理时,每个 token 只激活 2 个专家(Top-K=2),所以其计算量大致相当于一个 左右的稠密模型( 再加上 Attention 部分等)。
训练和推理加速: 更低的计算量意味着在相同的硬件上,模型的训练(每个 step)和推理速度可以更快。或者说,在相同的速度预算下,可以使用总参数量更大的 MoE 模型。
用SD生成的图像,只是想表达意思,大家忽略其中的错误文字啊
4.2 参数效率:用更少的计算撬动更大的模型容量
这与计算效率紧密相关,但侧重点不同。
解耦总参数量与计算量: 传统稠密模型中,参数量和计算量是强耦合的,参数越多,计算量越大。MoE 打破了这种耦合。你可以疯狂增加专家的数量 N,从而极大地提升模型的总参数量(Model Capacity),但只要保持 K 不变(或者很小),每个 token 的计算量增长得非常缓慢(主要只增加了 Gating Network 的一点点开销和路由开销)。
更高的模型容量: 更大的参数量通常意味着模型有更大的潜力去学习和存储知识,捕捉更复杂的模式。MoE 使得我们可以在计算预算可控的前提下,构建出参数量远超传统稠密模型的巨无霸。这被认为是 MoE 模型(如 GPT-4 据传使用了 MoE,以及 Mixtral)性能优越的关键因素之一。它们可能拥有万亿级别的总参数,但在推理时表现得像一个千亿级别的稠密模型一样快(甚至更快)。
再举个 :想象一下你的大脑。你可能学过很多知识(物理、化学、历史、编程、音乐...),这些知识的总量(总参数量)非常庞大。但是当你解决一个具体的物理问题时,你大脑主要调动的是物理相关的知识(激活的专家),而关于音乐理论的神经元可能就在“休息”(不激活)。MoE 就有点像模拟了这种大脑的工作方式。
4.3 专家特化(Specialization):理论上的优势与现实的挑战
理想情况: MoE 的设计初衷之一是希望不同的专家能够“术业有专攻”,各自学习处理输入数据的不同方面、不同类型的模式或不同领域的知识。例如,在多语言翻译任务中,可能有些专家擅长处理亚洲语言,有些擅长处理欧洲语言。在处理代码时,有些专家可能擅长 Python,有些擅长 C++。如果能实现这种特化,模型处理多样化任务的能力可能会更强。Gating Network 则扮演着识别输入属于哪个“领域”并将其导向相应专家的角色。
现实情况: 证明和度量专家是否真的实现了有意义的“特化”是比较困难的。一些研究表明,专家之间确实存在一定程度的功能分化,但可能不像我们想象的那么清晰和明确。有时,特化可能发生在更抽象的层面,比如某些专家处理更常见的模式,另一些处理更罕见的模式。而且,Gating Network 的决策也并非总是完美的“语义理解”,有时可能更多地是基于输入向量的某种聚类特性。
即使没有完美特化,依然有效: 重要的是,即使专家没有实现完美的语义特化,MoE 结构本身带来的计算和参数效率优势依然存在。只要 Gating Network 能够持续地、相对一致地将相似的输入路由到相似的专家组合,模型就能从中学习。
第五章:MoE 的挑战与解决方案:天下没有免费的午餐
听起来 MoE 这么牛B,是不是解决了大模型的根本矛盾?别高兴得太早,MoE 在带来巨大优势的同时,也引入了新的复杂性和挑战。
5.1 负载均衡(Load Balancing):别让劳模累死,懒汉闲死!
问题描述: Gating Network 的目标是为每个 token 选择最合适的 Top-K 专家。但如果 Gating Network “偏心”,总是倾向于选择某几个“明星专家”,而冷落其他专家,会发生什么?
明星专家过载: 被频繁选中的专家需要处理大量的 token,它们的计算负担很重。在分布式训练中,如果这些专家所在的 GPU 成为瓶颈,会拖慢整个训练速度。
冷门专家欠训练: 很少被选中的专家得不到充分的训练,它们的参数无法有效学习,变成了“凑数”的,浪费了模型容量。
Gating Network 倾向于“偷懒”: 如果没有约束,Gating Network 可能会发现,把所有 token 都交给同一个(或少数几个)专家处理是最“省事”(在损失函数上可能更容易优化)的选择,但这完全违背了 MoE 的初衷。
解决方案:引入辅助损失函数(Auxiliary Loss)
为了鼓励 Gating Network 更“公平”地分配任务,研究者们引入了负载均衡损失(Load Balancing Loss)。这个损失函数的目标是让每个专家处理的 token 数量(或 Gating 权重的总和)尽可能接近。一种常见的负载均衡损失:
假设在一个 batch 中有 T 个 token。对于第个专家,我们计算它被选中的“概率”或“分数”的总和(或者简单计算它被多少个 token 选为 Top-K 之一)。设 表示第个专家在 batch 中承担的“负载比例”(比如,处理的 token 数占总 token 数的比例)。设表示 Gating Network 输出的选中第个专家的平均概率(在 batch 上平均)。
一个常用的负载均衡损失(来自 GShard 论文)计算如下: 。这里 N 是专家数量, 是一个超参数,用来控制这个辅助损失在总损失中的权重。这个公式的直观理解是:它惩罚了和 同时都很大的情况。如果一个专家被赋予了很高的平均选择概率 ,同时它也实际处理了很高比例的 token ,那么这一项的损失就会很大。为了最小化这个损失,模型需要让 (实际负载)和 (分配概率)的分布都趋向于均匀。目标: 最小化会鼓励 Gating Network 将 token 更均匀地分配给所有专家,避免某些专家过载而另一些专家空闲。
权衡: 的值需要仔细调整。太小,负载均衡效果不佳;太大,可能会干扰主要的任务损失(比如语言模型的预测损失),影响模型性能。
负载均衡问题与解决:通过辅助损失,让专家“雨露均沾”。用SD生成的图像,只是想表达意思,大家忽略其中的错误文字啊
5.2 训练稳定性:MoE 有点“难伺候”
问题描述: 训练 MoE 模型有时比训练稠密模型更不稳定。这可能源于 Gating Network 的决策变化、负载均衡损失的引入、以及稀疏更新带来的梯度方差等问题。有时需要更小的学习率、更仔细的初始化或额外的稳定性技巧(如 Gating 值的噪声)。
解决方案:
学习率调整: 通常需要更小的学习率。
初始化策略: 对 Gating Network 的参数进行特殊的初始化可能有助于早期训练的稳定性。
Gating 噪声: 在 Gating 计算时加入少量噪声(例如,添加到 logits h 上),可以增加探索,有时能改善负载均衡和稳定性。
,然后再进行 Softmax 和 Top-K 选择。
专家容量因子(Expert Capacity Factor): 在实际工程实现中(尤其是在 TPU 上),为了处理负载不均衡和简化硬件处理,通常会设定一个“容量因子”(Capacity Factor, CF)。比如 CF=1.25,意味着每个专家被设计成最多能处理 batch 中 token 平均数(T/N)的 1.25 倍。如果某个专家收到的 token 超过了这个容量,多余的 token 就会被“丢弃”(overflow),不参与计算(或者采用其他策略)。这虽然简化了实现,但也可能导致信息损失。选择合适的容量因子是一个重要的调优参数。
5.3 通信开销:专家们住得太远怎么办?
问题描述: 在大规模分布式训练和推理中,模型的不同部分(包括不同的专家)通常分布在不同的计算设备(GPU/TPU)上。当 Gating Network 决定一个 token 需要由某个专家处理时,如果这个 token 当前不在那个专家所在的设备上,就需要进行网络通信,将 token 的表示发送过去。当 token 数量巨大、专家数量众多且分布广泛时,这种 All-to-All 的通信模式可能会成为严重的瓶颈。
解决方案:
高效的通信库: 使用优化的通信库(如 NCCL)和算法来加速 All-to-All 通信。
模型并行策略: 精心设计模型的并行策略,尽量将相互依赖的部分(比如同一个 MoE 层的 Gating 和 Experts)放置在通信带宽较高的节点集群内。
Switch Transformer 的简化: Switch Transformer 使用 Top-1 Gating,每个 token 只去一个专家,这在一定程度上简化了路由和通信问题(但负载均衡挑战可能更大)。
5.4 内存开销:参数虽多,但也占地方
问题描述: 虽然 MoE 的计算量(FLOPs)相对较低,但它的总参数量非常大。所有专家的参数都需要存储在内存(GPU HBM 或 CPU RAM)中。这导致 MoE 模型对内存容量的要求很高。一个拥有 1 万亿参数的 MoE 模型,即使推理时只激活一小部分,也需要足够的内存来容纳这 1 万亿个参数。
解决方案/现状:
模型并行: 将模型参数分散到多个 GPU 或机器上。这是目前训练和部署大型 MoE 模型的标准做法。
参数卸载(Offloading): 在推理时,可以将不活跃的专家参数暂时卸载到 CPU 内存或 NVMe 硬盘,需要时再加载回 GPU 内存。但这会增加延迟。
量化(Quantization): 使用较低精度(如 INT8、FP8)来存储和计算参数,可以显著减少内存占用,但可能略微影响模型精度。
第六章:代码示例:一个简化的 MoE 层实现
让我们来看一个更完整一点的 PyTorch MoE 层实现(简化版,仅关注核心逻辑,忽略分布式通信等复杂性)。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# 假设我们有一个简单的 FFN 作为 Expert
class Expert(nn.Module):
def __init__(self, d_model, d_ffn, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ffn)
self.activation = nn.ReLU() # 或者 GeLU 等
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
def forward(self, x):
x = self.linear1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.linear2(x)
return x
class SparseMoE(nn.Module):
def __init__(self, d_model, num_experts, k, d_ffn, dropout=0.1, noise_eps=1e-2):
super().__init__()
self.d_model = d_model
self.num_experts = num_experts
self.k = k
self.noise_eps = noise_eps # Gating 噪声的 epsilon
# Gating Network (简单的线性层)
self.gate = nn.Linear(d_model, num_experts)
# Experts (使用 ModuleList 管理多个 Expert 实例)
self.experts = nn.ModuleList([Expert(d_model, d_ffn, dropout) for _ in range(num_experts)])
# 用于负载均衡损失的统计 (实际实现中会更复杂)
self.expert_counts = torch.zeros(num_experts) # 记录每个专家处理的 token 数
self.total_tokens = 0
def noisy_top_k_gating(self, x, train, noise_eps=1e-2):
"""带噪声的 Top-K Gating"""
# x shape: (batch_size * sequence_length, d_model) -> (num_tokens, d_model)
logits = self.gate(x) # (num_tokens, num_experts)
# 在训练时添加噪声以改善负载均衡
if train and noise_eps > 0:
noise = torch.randn_like(logits) * noise_eps
logits = logits + noise
# 计算 Softmax 概率 (主要用于选择 Top-K)
probs = F.softmax(logits, dim=-1) # (num_tokens, num_experts)
# 选择 Top-K
top_k_probs, top_k_indices = torch.topk(probs, self.k, dim=-1) # (num_tokens, k)
# 创建稀疏的门控权重 (未归一化)
zeros = torch.zeros_like(probs) # (num_tokens, num_experts)
sparse_weights = zeros.scatter(1, top_k_indices, top_k_probs) # (num_tokens, num_experts)
# 归一化 Top-K 权重
norm_factor = sparse_weights.sum(dim=-1, keepdim=True) # (num_tokens, 1)
norm_factor = norm_factor + 1e-6 # 防除零
final_weights = sparse_weights / norm_factor # (num_tokens, num_experts), K 个非零值, 和为 1
return final_weights, top_k_indices
def compute_load_balancing_loss(self, gates, top_k_indices):
"""计算负载均衡损失 (简化版)"""
# gates shape: (num_tokens, num_experts) - 归一化后的权重
# top_k_indices shape: (num_tokens, k)
# 计算每个专家被选中的频率 f_i
# 使用 one_hot 和 sum 来统计每个专家被选中的次数
expert_mask = F.one_hot(top_k_indices, self.num_experts).sum(dim=1) # (num_tokens, num_experts), 值为 0 或 1
tokens_per_expert = expert_mask.sum(dim=0) # (num_experts,) - 每个专家处理的 token 数
# 计算每个专家的平均路由概率 P_i
# 这里用 gates 的均值近似 P_i (更准确的计算可能需要原始 logits)
avg_prob_per_expert = gates.mean(dim=0) # (num_experts,)
# 计算辅助损失 (参考 GShard)
# L_aux = N * sum(f_i * P_i)
# f_i = tokens_per_expert / num_tokens
# P_i = avg_prob_per_expert
num_tokens = gates.shape[0]
if num_tokens == 0: return 0 # 避免除以零
f_i = tokens_per_expert / num_tokens
P_i = avg_prob_per_expert
# 注意:原始论文的 loss 可能略有不同,这里是简化示意
load_balancing_loss = self.num_experts * torch.sum(f_i * P_i)
# 更新统计信息 (用于监控)
self.expert_counts += tokens_per_expert.detach().cpu()
self.total_tokens += num_tokens
return load_balancing_loss
def forward(self, x):
# x shape: (batch_size, sequence_length, d_model)
original_shape = x.shape
num_tokens = original_shape[0] * original_shape[1]
x = x.reshape(num_tokens, self.d_model) # (num_tokens, d_model)
# 1. Gating 决策
# final_weights: (num_tokens, num_experts), 稀疏, K 个非零, 和为 1
# top_k_indices: (num_tokens, k), 被选中的专家索引
final_weights, top_k_indices = self.noisy_top_k_gating(x, self.training, self.noise_eps)
# 计算负载均衡损失 (只在训练时计算)
if self.training:
load_balancing_loss = self.compute_load_balancing_loss(final_weights, top_k_indices)
# 在实际训练中,这个 loss 会乘以一个系数加到总 loss 上
# self.loss = main_loss + alpha * load_balancing_loss
else:
load_balancing_loss = 0 # 推理时不计算
# 2. 路由和专家计算 (这里用循环模拟,实际需要高效的并行实现)
# 初始化输出张量
output = torch.zeros_like(x) # (num_tokens, d_model)
# 将 final_weights 和 top_k_indices 展平,方便索引
flat_top_k_indices = top_k_indices.flatten() # (num_tokens * k,)
flat_final_weights = final_weights.flatten()[final_weights.flatten().nonzero(as_tuple=True)[0]] # (num_tokens * k,) - 只取非零权重
# 创建一个 token 索引,指示每个权重/索引对应哪个原始 token
token_indices = torch.arange(num_tokens, device=x.device).repeat_interleave(self.k) # (num_tokens * k,)
# 模拟将 token 发送给专家并计算
# 这是一个效率较低的实现方式,仅为演示逻辑
# 实际高性能库会使用复杂的 index/gather/scatter 操作和并行计算
expert_outputs = []
current_weight_idx = 0
for i in range(self.num_experts):
# 找到所有需要由专家 i 处理的 token 的索引
mask = (flat_top_k_indices == i)
selected_token_indices = token_indices[mask] # 这些 token 需要专家 i 处理
if selected_token_indices.numel() > 0:
# 获取这些 token 的输入
expert_input = x[selected_token_indices] # (num_selected_tokens, d_model)
# 通过专家 i 计算
expert_output = self.experts[i](expert_input) # (num_selected_tokens, d_model)
# 获取对应的权重
expert_weights = flat_final_weights[mask].unsqueeze(1) # (num_selected_tokens, 1)
# 加权输出并累加到最终结果 (使用 index_add_ 进行原地累加)
output.index_add_(0, selected_token_indices, expert_output * expert_weights)
# 恢复原始形状
output = output.reshape(original_shape) # (batch_size, sequence_length, d_model)
# 返回最终输出和辅助损失 (训练时使用)
return output, load_balancing_loss
# 使用示例
# d_model = 512
# num_experts = 8
# k = 2
# d_ffn = 2048 # 每个专家的中间层维度
# moe_layer = SparseMoE(d_model, num_experts, k, d_ffn)
#
# # 假设输入
# input_tensor = torch.randn(4, 10, d_model) # (batch_size=4, seq_len=10, d_model=512)
#
# # 前向传播
# moe_layer.train() # 设置为训练模式以计算辅助损失
# output_tensor, aux_loss = moe_layer(input_tensor)
#
# print("Output shape:", output_tensor.shape)
# print("Load Balancing Loss:", aux_loss)
#
# # 推理时
# moe_layer.eval()
# with torch.no_grad():
# output_tensor_eval, _ = moe_layer(input_tensor)
# print("Eval Output shape:", output_tensor_eval.shape)写在最后
MoE 技术就像给庞大的神经网络装上了一个聪明的“调度系统”,让它在拥有渊博知识(海量参数)的同时,也能灵活高效地思考(低计算量)。它不是完美的,有自己的挑战和代价,但它确实为我们突破模型规模和效率的瓶颈提供了一条极具潜力的路径。
希望这篇(可能过于)详细的介绍,能让你对 MoE 有一个清晰的认识。下次当你听到 GPT-x 又用了多少万亿参数,或者某个新模型又快又强时,也许就能想到背后可能有 MoE 这个“幕后功臣”在默默地进行着“专家调度”了。
这篇文章中涉及了很多的公示,也有一些不太恰当的比喻,当然,还有很多使用SD画的辅助理解的图。内容太多,如果其中有错误,欢迎指出。